
Gradient Descent in Machine Learning
According to the Merriam-Webster dictionary, Gradient is defined as the rate of regular graded ascent or descent. Did you know that gradient descent is very important in machine learning algorithms? It is one of the most widely used optimization strategies in modern machine learning and deep learning models. When training ML models, this is an important and easy step to implement.
Gradient descent works by finding the local minimum for a cost function by repeatedly changing the model parameters. The cost function is the sum of the difference between squared predicted output and squared outcome. In the cartesian coordinate system, the cost function has the form of a parabola. The work of the gradient descent is to find the value of x which reduces the cost function y.
The gradient descent can be imagined as a person walking towards the point that is local minima. The main aim of the algorithm is to determine which direction to walk and how big or small the steps should be. Gradient is the slope of the function calculated as partial derivatives. The larger the slope, the faster a model can learn. So in effect the person can take bigger steps. But as slope reduces, the step size reduces.
In terms of an equation it can be represented:
New pos = current pos - small step*(in direction of fastest increase)
The steps are taken until it converges at the local minima. The important thing is the learning rate which should not be too large, since then the steps would overshoot the minima and determine a wrong minima. If the rate is too small, it would take infinitely long to converge.
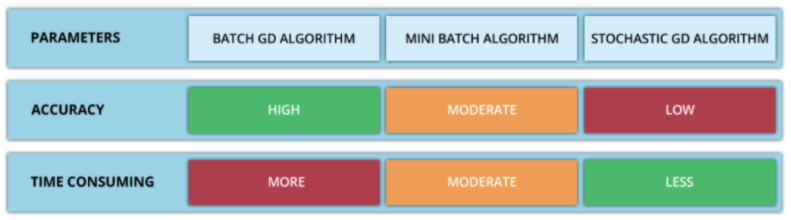
There are three types of gradient descent:
Batch gradient descent: here the entire batch is taken to calculate the new parameters until then the algorithm doesn’t update. It is efficient computationally. It doesn’t produce the most optimum results as it stabilizes.
Stochastic gradient descent: The parameters are updated after every training sample. It is computationally expensive but produces good results.
Mini-Batch gradient descent: This is a combination of the above two, where smaller batches are taken and it is less expensive computationally and works well.
Picture Source: hackerearth.com